
内容:利用 Excel vba 控件:winhttp 可以轻松从网站上绕过繁琐的登录获取想要的数据。(需要一定的 VB 编程和 HTTP 基础),本次案例是绕过B站登录获取个人收藏的视频列表。
适用人群:适用经常用Excel办公人员,并且需要一定的自动化处理数据。
适用场景:需要频繁从网上获取数据。
使用方式:可以看我发布的文章:Excel vba 利用 Cookie 绕过网站登录爬取数据(vba网抓技巧)。本文使用的源码就是这个资源。
2023-03-04 08:01:37
31KB
1
天天基金爬虫
爬取天天基金网上的所有基金,辅助对基金投资的选择
购买基金前,请务必在官方网站上确认爬取的数据无误!
2021-01-24更新 若存在问题,请切换回Release版本
功能特性
爬取基金的近1、3、6月,近1、3年及成立来的收益率,当前基金经理及其任职时间、任职来的收益率及总的任职时间
模仿tcp的拥塞避免的线程数量控制,慢开始,当出现错误时,线程最大值减半,成功则线程最大值+1
爬取全部数据需要505s,瓶颈为网站的反爬策略
结果展示
2021-01-24 共有10203个基金
食用方法
环境依赖 运行环境Python3.7 依赖见requirements.txt
下载所有.py脚本文件(除MonkeyTest外)
爬取基金数据
运行CrawlingFund.py并等待
筛选基金 还没做
基金分析 也没做
文件结构
-CrawlingFund 爬取主文件,描述整个的
2023-03-02 14:36:54
234KB
1
招标搜索软件使用说明
软件使用类似于百度的蜘蛛引擎,每日爬行全国招标信息、政府采购类网站,从中提取出各类有效的招标数据或政府采购信息,用户下载我们的招标搜索软件,免安装即可搜索使用,就可搜索到全国最新的各类招标中标政府采购等信息,从而为企业解决了在获取各类招投标信息时,渠道单一、只使用某一或几个网站进行搜索、导至错失大量有用信息无法知晓。软件在操作上、我们力求以最简单的操作方式来达到最理想的搜索结果,您只需要选择几个不同的搜索条件,即可让你看到意想不到的信息。
采购招标信息
政府网站(公共资源交易中心,政府采购中心)、大型企业网站、代理机构网站等机构采购招标信息,会员(采购商)自主发布采购招标信息,供用户查询。内容包含投标要求、业主、招标公司联系人、联系方式、及购买标书的时间、地点等,每日更新公开招标信息。
政府采购
各省、市、县政府采购单位发布的询价类、比选、竞争性谈判及单一来源采购类信息。
企业采购
国内各大企业、集团公司所发布的直接采购信息,用户可通过非招标的形式,直接和业主方联系,洽谈供货及长期合作事宜。
会员招标采购
中机采招网广大用户发布的招标信息,包括招标内容、采购单位以及联系人、联系方式。中机采招网可推荐符合采购单位要求的认证企业前去参与。
变更通知
是在发布招标公告后补充公告、变更公告、废标公告、重新招标等信息,使用户可以及时获知,并有效的对投标工作做出相应方案调整,以免因此导致投标失误。
标书下载
部分招标项目可向用户提供电子版标书下载服务,标书内容包含项目采购清单、商务文件、技术参数、评标办法、报名表等,省去因盲目购买标书而损失的财力和时间成本。
中标信息
政府网站(公共资源交易中心,政府采购中心)、大型企业网站、代理机构网站等机构中标信息,供用户查询。提供中标单位、中标项目、中标金额,为会员提供直接供货渠道。更有利于会员为中标企业在后期分包工作中,做好提前介入工作。
招标数据查询
中机采招网庞大招标数据信息,可为用户提供历史招标数据,统计、导出、分析提供相关数据支持。
中标数据查询
中机采招网庞大中标数据信息,可为用户提供历史中标数据,内容包含采购单位、中标单位、中标金额等,对用户的数据统计、导出、分析提供相关数据支持。
项目导出
用户可针对中机采招网项目库中所感兴趣的项目,按地区和时间进行分别汇总,并导出保存在本地电脑上进行存档备案。
数据库 (招标)
根据用户需求,以表格形式汇总近一个月内各行业、各领域招标采购数据信息,为用户做数据分析提供支持服务。
数据库 (中标)
根据用户需求,以表格形式汇总近一个月内各行业、各领域中标数据信息,为用户做数据分析提供支持服务。
数据库 (企业)
供包含业主、招标代理机构及相关单位、供应商、政府采购中心等企业数据库在线查询服务。
2023-03-02 11:01:38
24KB
1
基于scrapy编写的爬虫,能够爬取城市二手房的各种信息,比如房价、面积、所处位置等十分方便易用,并采用Beautifulsoup进行页面解析无视反爬机制
2023-02-28 16:48:02
195KB
1
本程序可以连续爬取一个或多个新浪微博用户(如胡歌、迪丽热巴、郭碧婷)的数据,并将结果信息写入文件或数据库。写入信息几乎包括用户微博的所有数据,包括用户信息和微博信息两大类。
2023-02-28 14:16:16
102KB
1
提供批量截取子网页.py的全部源码,py3运行,适应性修改有说明
- 用于大批量的资源链接拷贝到Excel表,集中后可分类排序规整。
- 生成子网页文件a.html,可本地打开此网页,拷入Excel表格,主列取得资源标题和链接,以及其他列。
2023-02-28 09:50:16
3KB
1
> ### python爬虫爬取百度百科页面
> 简单爬虫框架:
> 爬虫调度器 -> URL管理器 -> 网页下载器(urllib2) -> 网页解析器(BeautifulSoup) -> 价值数据
目录结构:
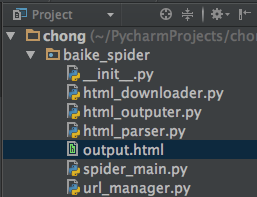
> 注:mac osx下用alt+enter添加相应方法
- (爬虫调度器)spider_main.py
- (url管理器)url_manager.py
- (下载器)html_downloader.py
- (解析器)html_parser.py
- (数据输出)html_outputer.py
> 运行程序spider_main.py可进行爬取页面,最终文件输出为output.html,里面包含词条和词条解释,爬取完毕。
output.html:
![](http://images2015.cnblogs.com/blog/763083/201
2023-02-25 13:06:49
10KB
1
通过python爬虫采集城市的酒店数据
内容概要:使用python采集酒店数据
适用人群:做酒店数据市场调研,数据分析报告的人群
使用场景及目标:需要依靠python3环境,执行爬虫脚本
其他说明:需要使用开发者工具捕捉网站中的目标城市对应的cityCode,城市编号,如有侵权,联系删除
2023-02-24 23:31:27
7KB
1