
主要介绍了如何使用python爬虫爬取要登陆的网站,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
2024-04-30 18:21:48
223KB
1
本文实例讲述了Python爬虫爬取新浪微博内容。分享给大家供大家参考,具体如下:
用Python编写爬虫,爬取微博大V的微博内容,本文以女神的微博为例(爬新浪m站:https://m.weibo.cn/u/1259110474)
一般做爬虫爬取网站,首选的都是m站,其次是wap站,最后考虑PC站。当然,这不是绝对的,有的时候PC站的信息最全,而你又恰好需要全部的信息,那么PC站是你的首选。一般m站都以m开头后接域名, 所以本文开搞的网址就是 m.weibo.cn。
前期准备
1.代理IP
网上有很多免费代理ip,如西刺免费代理IPhttp://www.xicidaili.com/,自己可找一个
2023-04-05 17:58:14
130KB
1
可以使用python实现基本的图片爬取和保存功能,用户可以根据自己需求自定义要爬取的链接,但是相应的也要根据网页结果更改部分代码,代码清晰,思路明确,适合学习python爬虫爬取图片参考。
2023-03-08 22:06:44
1KB
1
> ### python爬虫爬取百度百科页面
> 简单爬虫框架:
> 爬虫调度器 -> URL管理器 -> 网页下载器(urllib2) -> 网页解析器(BeautifulSoup) -> 价值数据
目录结构:
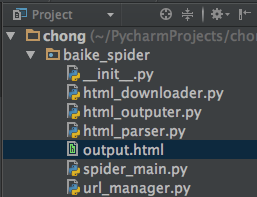
> 注:mac osx下用alt+enter添加相应方法
- (爬虫调度器)spider_main.py
- (url管理器)url_manager.py
- (下载器)html_downloader.py
- (解析器)html_parser.py
- (数据输出)html_outputer.py
> 运行程序spider_main.py可进行爬取页面,最终文件输出为output.html,里面包含词条和词条解释,爬取完毕。
output.html:
:
try:
r = req.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def parasePage(ilt, html):
try:
plt = re.findall(r'\"view_price\"\:\"[\
2022-12-15 21:38:18
83KB
1
你好
由于你是游客
无法查看本文
请你登录再进
谢谢合作。。。。。
当你在爬某些网站的时候
需要你登录才可以获取数据
咋整?
莫慌
把这几招传授给你
让你以后从容应对
登录的常见方法无非是这两种
1、让你输入帐号和密码登录
2、让你输入帐号密码+验证码登录
今天
先跟你说说第一种
需要验证码的咱们下一篇再讲
第一招
Cookie大法
你平常在上某个不为人知的网站的时候
是不是发现你只要登录一次
就可以一直看到你想要的内容
过了一阵子才需要再次登录
这就是因为 Cookie 在做怪
简单来说
就是每一个使用这个网站的人
服务器都会给他一个 Cookie
那么下次你再请求数据的时候
2022-05-29 11:31:34
227KB
1